Back to cleaning...
- Andrea Osika
- Dec 18, 2020
- 4 min read

Updated: Jan 25, 2021
I was catching up with a fellow data colleague and shared that I was looking for some practice with data cleaning. I've taken some time to go a little deeper into SQL and visualization with Tableau (oooh-next week's post! I forgot to show you what I learned!) and realized my Python game had rusted a little. I needed some data cleaning to practice around on since modeling demands useable data. The colleague I mention is very much into poli-sci and found a data set that was in .txt format and contained nested data. It was a mess.
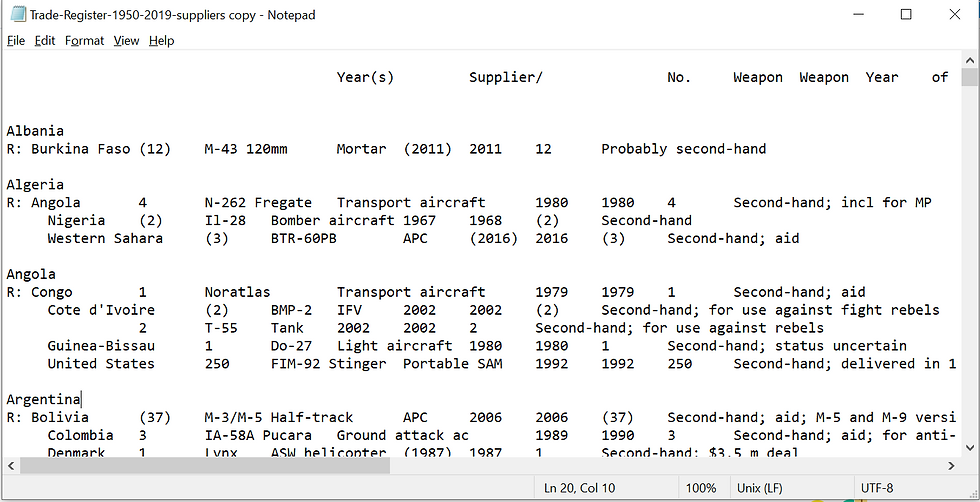
When I imported it into pandas, even more so:
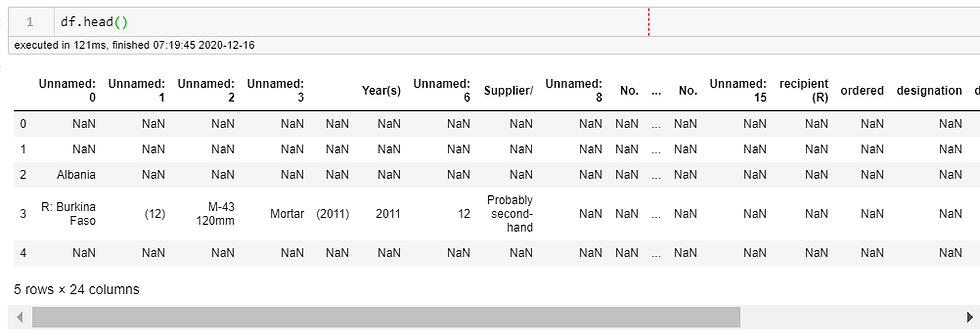
The suppliers and recipients are all in the same column and the subsequent data after each recipient is indented one more. I began investigating ways to move columns around. I looked at .pivot(), .unstack(), and other ways.
I thought about how I might tackle identifying who the suppliers were since they came in the row above the first recipient (indicated by the 'R:') and how I could collect those that came after... I noticed some other rows that were indented by another level as well. I thought about making a dictionary as well. But really, all wanted was to shift the columns over...one here one there... When I was talking to my colleague, he mentioned that he was thinking of the .shift() function he never got to use that much. I remembered .shift() from a time series project I recently worked on and was intrigued.
I first isolated the suppliers by finding the first row of recipients (R:) :
#all the suppliers come right before the recipients which are indicated by having an R:
#isolating those first:
df['r'] = df.iloc[:,0].str.find('R:')
df.head()and creating an index for the recipients,
#idendifying index list of all the recipients
index = df.index
recps = index[df.iloc[:,0].str.find('R:') == 0]
recpswhich made making a list of suppliers quite easy:
#identifying index for all the suppliers
sups = recps -1
supsI started cleaning a little more, but making columns that made sense (sups_recips to me makes sense - it's suppliers and recipients, and I knew I'd delete it):
#renaming Unnamed 0: since it throws key errors
df.rename(columns = {'Unnamed: 0':'sups_recips'}, inplace = True) #creating a column to shift the values into:
df.insert(0, 'Supplier', value=' ')Then I made some new columns separate from the original dataframe those using .shift().
shift() takes several arguments. Here are the defaults:
periods=1,
freq=None,
axis=0,
fill_value=None
It's more frequently used in time-series. In this case, we are using the functionality of shifting the number of periods for the columns. Since my value is -1, I'm manipulating the values by one value prior, and since I'm operating on the 1 axis, I'm shifting my values by one column to the left. Slick, right?
#shifting the values over by pulling the indexes and adjacent values
col= df.loc[sups, ["Supplier", "sups_recips"]].shift(-1, axis=1, fill_value=" ")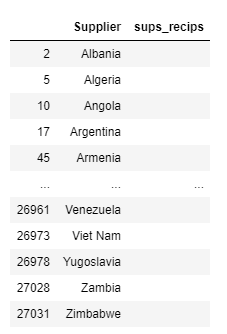
This gave me the shape to fill in the values in the column I created :
#filling it in
df['Supplier'] = col['Supplier']Next: I had to pull out all the recipients and put them in their own column. I isolated them but finding all the blanks in the newly formed Supplier column:
recip1idx = df[df['Supplier'].isnull()].index.tolist()and filled in all the suppliers for each recipient:
df['Supplier'].ffill(inplace=True)Then, repeated the process, but shifted the columns the other way, just because I could:
1) make a column
df.insert(2, 'Recipient', value=' ')2) shift it
#shifting the values over by pulling the indexes and adjacent values
col1= df.loc[recip1idx, ["sups_recips", "Recipient"]].shift(1, axis=1, fill_value=" ")3) replace the values:
df['Recipient'] = col1['Recipient']I got rid of the column that had originally contained both the suppliers and the recipients:
df.drop('sups_recips', axis=1, inplace=True)and renamed columns. It was really starting to bug me and took another look:
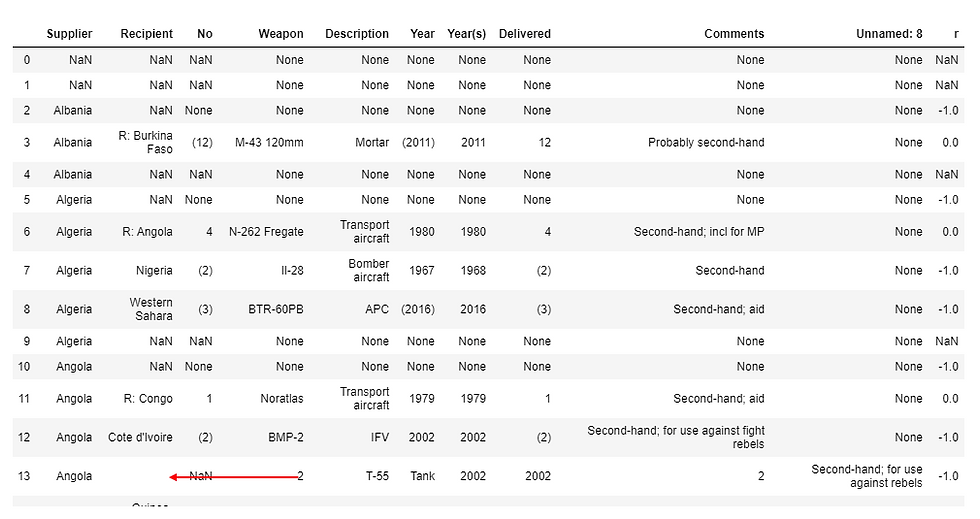
I can see where in the case of row#13 needs to be shifted over. Luckily, I know how and get to practice some more.
To this, I need to identify which indices need to be moved:
I found the key value for that line... It was tricky since it wasn't a null value. I tried one space with no luck but isolated it with a little slicing and copied it and created a list of indices (It looked like four spaces, but honestly, it didn't work until I copied and pasted the value):
shft_recip = df['Recipient'] == ' '
sups_idx = [i for i, true in enumerate(shft_recip) if true]then... shifting happened by reassigning the indices with the values of the next column over shifted over by one, then filling in the column space wouldn't be needing anymore with blanks:
#reassigning the indexes with the shifted values:
df.loc[sups_idx] = df.loc[sups_idx].shift(-1, axis=1, fill_value=" ")Now we're talking:
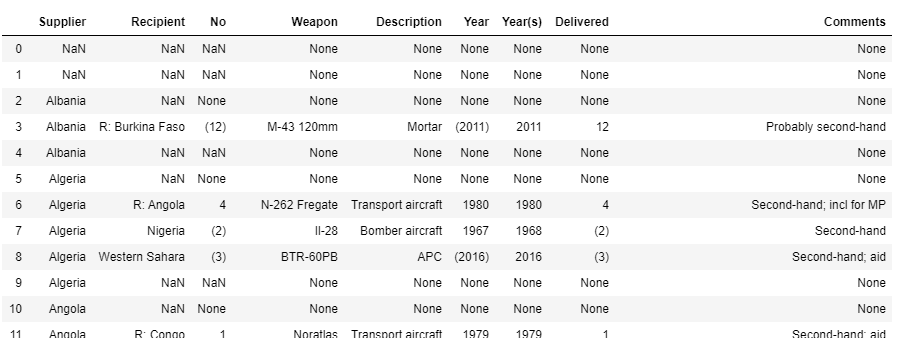
sooo.. now we just need to get rid of those pesky blanks. Again, isolate the indices of the ones we want. In this case, I want all those who have a value in Supplier and not in Recipient:
dfsr = df[['Supplier', 'Recipient']]
dels = dfsr[dfsr['Recipient'].isnull()].index.tolist()and get rid of 'em:
df.drop(dels, axis=0, inplace=True)...and we don't need that 'R:' anymore:
df['Recipient'] = df['Recipient'].str.replace('R:', "")...and get rid of some other stuff we don't need in a couple of columns that impairs the useability of numeric values and dates:
df['No'] = df['No'].str.replace(')', "")
df['No'] = df['No'].str.replace('(',"")...how beautiful! Clean, organized, functional data:
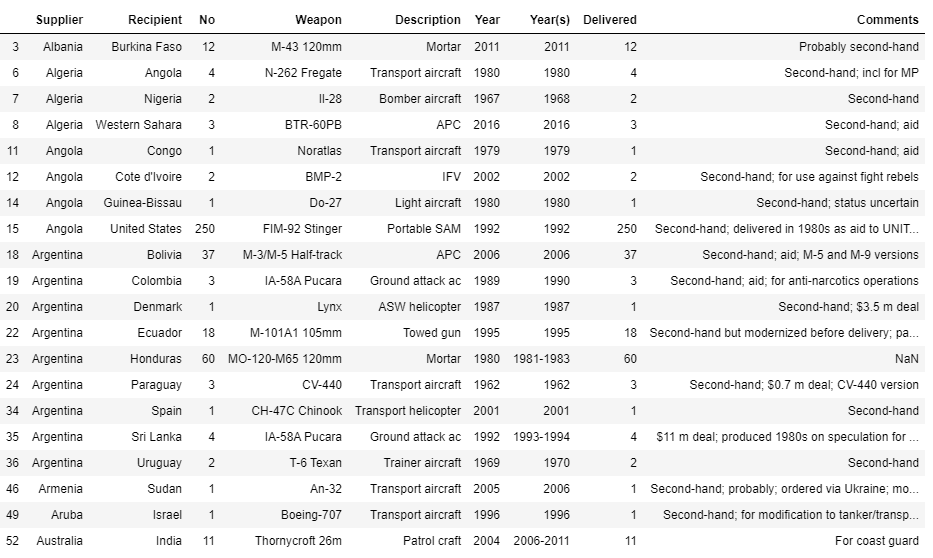
Now we can more efficiently .pivot() and .unstack() this data, visualize and use the data!
A special thanks to my colleague https://github.com/MichaelBurak/ who inspired and gimped me through the process.
To see the full notebook: https://github.com/andiosika/shifting
More reading on .pivot() and .unstack()



Comments