Preprocessing text in natural language processing
- Andrea Osika
- Mar 11, 2021
- 3 min read

When given a choice of projects to work on for analysis, I find that oftentimes it involves natural language processing. Basically, the data being analyzed is text. I can't help but want to know what people are talking about. In other posts, I've written about the outcomes or models I used. However, before we even get to that part - as in all analysis, cleaning has to take place first.
Honestly, the project I was thinking about had some dirty words - for real. The idea was to train a model to identify toxic language in public forum discussions. I'm all for freedom of speech, but considering some platforms it might come in useful to keep things clean- 'ahem'.
In natural language processing, we take the text data and tokenized it or turn it into numeric values. From there, we can feed it into our model to be classified. Some things to keep in mind when doing this - we need things as uniform as possible for proper evaluation.
When we get this data loaded in, we can see at first glance things look like they might need some attention:
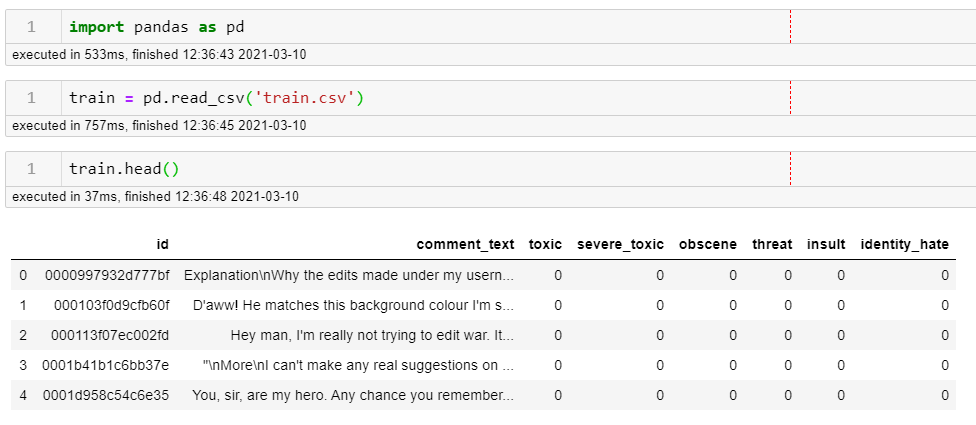
When we look at the 'comment_text' we can see those pesky \n that represents a new line. Since this was written in a public forum, we see a lot of new lines created, so I'll get rid of those using regex - or regular expressions. This is a helpful regex cheat sheet if you want one to understand it or for more reference.
# replacing all \\n with a blank space
train['comment_text'].replace(r'\s+|\\n', ' ', regex=True, inplace=True) 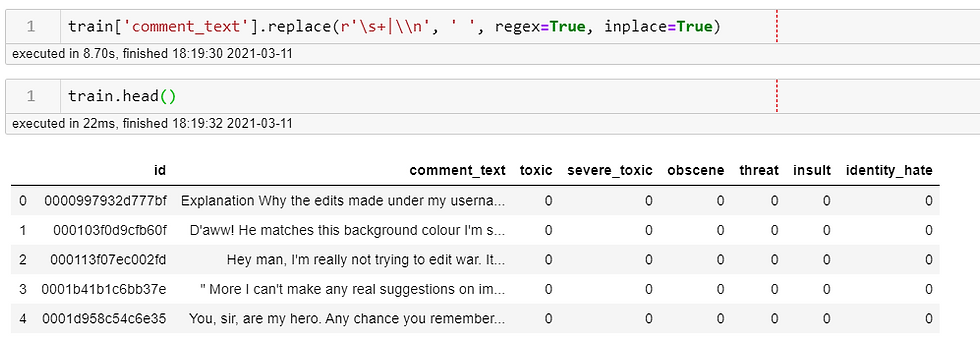
Next, we need to simplify the text so we can understand what's going on more concisely.
When working with text data, we like to make things as uniform as possible during analysis in the corpus - or the totality of the words being analyzed. For example, the word 'Carrot' and 'carrot' mean the same thing to you and me, right? As tokenized data - they mean two different things. This is because one is capitalized and one is not. For this reason, it's generally a good idea to put all words in lowercase and remove punctuation.
Another tool used to keep consistency for analysis is called lemmatization. Lemmatization usually refers to breaking words down into their most simple term and make a lemma. An example would be words like 'singing' and 'singer' would be boiled down to 'sing'.
Also, it's a good idea to get rid of words that are generally used a lot in the English language but carry very little intrinsic meaning - words like 'the', 'a' and so on. These are called stopwords and they need to be removed.
Keeping all this in mind, I created a function that would take in a list of words and do all of the things mentioned above:
def clean_comment(comment):
'''Lemmatizes, removes capitalization, punctuation and 'stopwords' from the lemmatized tokens,returns data in the dataframe for modeling in a "clean" state comment - a text string'''
import nltk
from nltk.corpus import stopwords
import string
#splitting sentences into tokens
tokens = comment.split()
#instantiating Lemmatizer and lemmatizing words
lemmatizer = nltk.stem.WordNetLemmatizer()
lemma_tokens = [lemmatizer.lemmatize(token) for token in tokens]
stopwords_list = stopwords.words('english')
#adding additional words found later - use whatever are relevant
stopwords_list += ("''","``", "'s", "\\n\\n" , '...', 'i\\','\\n',
'•', "i", 'the', "'m", 'i\\', "'ve", "don\\'t",
"'re", "\\n\\ni", "it\\", "'ll", 'you\\', "'d",
"n't",'’', 'article', 'page', 'wikipedia', ' ',
"\\\'\\\'\\\'\\\'\\\'\\\'", '\\n\\n-',
"\''",'a','e', 'i', 'o','u', 'i\'m', 'i\'ll',
'what\'s', "i\'ve", "i\'d'" )
#remove punctuation, capitalization, and stopwords
stopwords_list += list(string.punctuation)
stopped_tokens = [w.lower() for w in lemma_tokens if w.lower() not in stopwords_list]
return ' '.join(stopped_tokens)it puts them all back together for analysis.
To put this into play:
# simple for loop to clean the text
for text in train['comment_text']:
clean_comment(text)From there, going to separating the data for analysis is a bit of a snap. The X will be the text and y is our target, so target classes:
# slicing the columns I want for y:
tr_classes = train.iloc[:,2:]
tr_cols = tr_classes.columns.to_list()
tr_cols
['toxic', 'severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate']
y=train[tr_cols]
X = train['comment_text']From there you can use these variables in your model. Support Vector Machines have great success in NLP, as does deep neural networks.
What tips and tricks do you use for preparing your text data for modeling?
For more reading on regex: https://towardsdatascience.com/a-simple-intro-to-regex-with-python-14d23a34d170
cover image by Amal_cp



Comments