Python V SQL :
- Andrea Osika
- Feb 17, 2021
- 3 min read

I'm looking for a new place to apply my newfound skills. In this search, I see SQL. A lot. In a recent project I was working on, I was asked to do some analysis using excel, SQL or whatever language I am most comfortable with. The result: I ended up having a thought I NEVER thought I'd have 2 years ago which was "This would be so much easier in Python!" After spending some time on Random Forest, NLP, and Neural Networks it was refreshing to just query and do some basic analysis. It got me thinking about what commands I use in Python that translates to SQL and vice-versa.
I started with a raw dataset consisting of two tables. I visualized them in excel and started with low-level data manipulation there - removing data that needed to be extracted, obvious outliers etc. I then uploaded the data into an Oracle database to practice some SQL.
In SQL to join the two tables, I created a join on User_ID :
CREATE TABLE S_PROF AS
(SELECT i.User_id, i.student_grade, iready_score, iready_placement, s.score, s.proficiency
FROM SSCORES s
JOIN ISCORE I ON S.User_ID = I.User_ID);and as I began to try and visualize and pull records I had that thought I reference above. Python, please!!! so..... in Python I used .merge()
df = pd.merge(sscore, iscore, left_on='UserID', right_on='UserID')Merge is more useful for side-by-side or simple comparisons. This function offers more flexibility compared to another Python function: .concat() because it allows combinations based on a condition. In the code above, I'm asking to merge where the 'UserID' values are the same in the two tables.
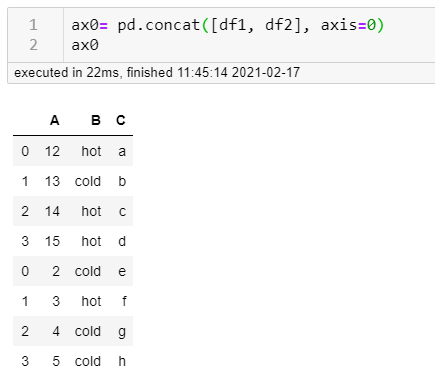
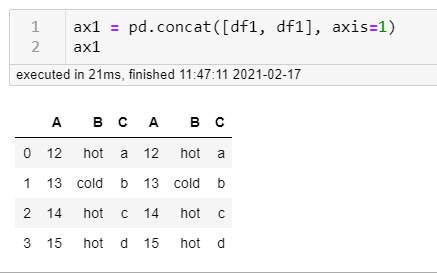
You can use .concat() along rows (on top of each other) or columns (side-by-side) depending on the value of axis parameter which might be handy as well. If you concatenate them on the 0 axis, it means you stack them on top of each other, if you use 1, it's side-by-side. If you're visual like me, this might help. Let's consider we have two dataframes:


0=axis concat stacking on top of each other:
1 axis concat: side by side joining
I have since learned that in SQL, you can use UNION to stack one dataset on top of the other. I found an explanation here but basically, you write two select statements:
SELECT * FROM table_part1
UNION
SELECT * FROM table_part2A couple of rules that I'm literally copying from the site referenced in the link above:
"UNION appends distinct values. More specifically, when you use UNION, the dataset is appended, and any rows in the appended table that are exactly identical to rows in the first table are dropped. If you'd like to append all the values from the second table, use UNION ALL. You'll likely use UNION ALL far more often than UNION. "
That is one example of how pandas and SQL have similar functionality.
I was thinking more about similar functions. When I'm looking at the .head() of a dataframe in python it will display the number of rows indicated in the parameters between the parenthases.
To get the top three rows:
In Python:
df1.head(3)In SQL:
SELECT TOP (3) col
FROM datasetI think I like Python better since it seems to be more succinct. It's true to, in the case where we are trying to find null values:
In Python:
df['column'].isnull()In SQL:
SELECT column
FROM table
WHERE column IS NULLor what about when we are looking to order how values are returned?
In Python:
df.sort_values(by=['column'])In SQL:
SELECT column1, column1
FROM table
ORDER BY column2Grouping... it seems sooo simple in Pandas. You'd simply start by using df.loc - which now that I think about it is like the SELECT function in SQL:
SELECT column
FROM table
another crossover function... but I digress... ok, back to grouping using df.loc:
In Python:
df.loc[:'column1', 'column2', 'column3'].groupby('column2').sum()In SQL:
SELECT column1, column2
FROM table
GROUP BY SUM(column2)I honestly struggled a little when I had to add a column in SQL. In Pandas it's pretty simple. You create the column as a variable and then tell it what condition you want to populate the column:
df['totals'] = df['column1']+df['column2']
In SQL:
ALTER TABLE table ADD column
I guess it's because I learned more Python than SQL and spent more time on it, but to me, Python seems more flexible. I understand SQL was written more 'like English' and I'm getting better at it with time and practice. I guess I didn't realize how similar they were after all. I'm sure for straight querying SQL is more streamlined and computationally less expensive. And for some functions, it's more simplistic in terms of lines of code. Leave me an example/drop a comment here to inspire me?



Comments