Tuning a Random Forest
- Andrea Osika
- Jan 21, 2021
- 5 min read

Well, the response to my prior post was kind of underwhelming but I thought I'd revisit how the heck I tuned that model with the hyper-imbalanced dataset. Tuning it, means finding that sweet spot of not having just the right amount of trees making the decisions based on certain parameters.... so you can see what the trees are telling you.

In case you didn't click on the link in the first sentence, I'll bring you up to speed. The dataset used in this evaluation was created by a project created by a UK based platform-solutions company called Nexoid. At the start of the pandemic, Nexoid noted that there was a lack of large datasets required to predict the spread and mortality rates related to COVID-19. They took it upon themselves to create and share data in an effort to better understand the factors. I used the data to try to identify what self-reported behaviors, biologic factors, or environmental factors were most important for those who tested positive for COVID-19.
The questionnaire used to collect data has since undergone several versions and several features collected during this sample are no longer being tracked. Data for this observation was collected between March 27 - April 10 of 2020, and only a very small rate (.13%) of respondents reported testing positive for COVID-19. It should be noted that at this time there was a shortage of tests available in the United States and latency in receiving results was up to two weeks. The intention of this classification project was to identify primary contributing factors for contracting COVID-19 based on this knowledge.
After trying various classification methodologies including XGboost and scikitlearn's Decision Tree Classifier, I ended up with Random Forest performing best in preliminary testing. Despite the outlook, I had a few blockers still in my way: imbalanced data, and a large dataset that running gridsearch on with my laptop got computationally expensive. I was left to manually tune the RandomForest on my own.
Here's how I attacked the problem:
I looked at each of the hyperparameters and evaluated how each would affect the outcome.
criterion: You can use either 'gini' or 'entropy'. 'gini' uses information gain; where the entropy is calculated using log values. I've heard that gini is used as default since it's less computationally expensive and also tends to classify better. It ended up the one I used and have since heard that entropy might help with the imbalance.
max_depth: this tells us how deep we want our tree to isolate factors in determining what effects the target. If we go too deep, we gather too much information to make an accurate prediction. This is when overfitting happens. The idea is to find that sweet spot between having too simple of a tree and missing information or growing one that is too complex to accurately make predictions.
max_features: This parameter tells us how many features to look for when making the best split. The default is to take all the features into account (my count is 43 to begin with, but once I encoded it was many more). You can tell it how many by setting an integer value or if you assign a float, as scikit learn puts it: "then max_features is a fraction and int(max_features*n_features) features are considered at each split" . I ended up in the end using a percentage rather than forcing a set number in.
n_estimators: This is the number of trees you want to create before collecting voting or averages of predictions - it's how dense you want your forest to be.
The ones I talk about above were those I was most concerned with. I attempted to find the best values for each using GridSearch and kind of eye-balling it. Clearly both gini and entropy were evaluated:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(class_weight='balanced', random_state=123)
## Set up param grid
param_grid = {'criterion':['gini','entropy'],
'max_depth':[7,8, 10,15],
'max_features':[70, 80, 85, 90,100],
'n_estimators' :[75,100,125, 150]}
## Instantiate GridSearchCV
grid_clf = GridSearchCV(rf_clf, param_grid, cv=skf)
#fit the model
grid_clf.fit(X_train_rus, y_train_rus)Then it was time to see what I'd come up with. I haven't talked about cross-validating yet. But it's something you use to run the process a couple of times over and re-sampling the data to check validity the higher the score, the better. In this case, I used the average of three runs:
mean_rf_cv_score = np.mean(cross_val_score(grid_clf, X_train_rus, y_train_rus, cv=3))
mean_rf_cv_scorewhich rendered a cross-validation score of .7968...
0.7968098708605037
not too bad, and here were the parameters the model decided on:
print(f" Best parameters found via GridSearchCV:{grid_clf.best_params_}") Best parameters found via GridSearchCV:{'criterion': 'gini', 'max_depth': 10, 'max_features': 70, 'n_estimators': 100}
and
The best estimators:
print(f" Best estimators found via GridSearchCV: {grid_clf.best_estimator_}")Best estimators found via GridSearchCV: RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight='balanced', criterion='gini', max_depth=10, max_features=70, max_leaf_nodes=None, max_samples=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=None, oob_score=False, random_state=123, verbose=0, warm_start=False)
Based on this recommendation, I built a model and set a random state so I could replicate this if it turned out to be descent:
rfgs_clf = RandomForestClassifier(criterion='gini', max_depth=10, max_features=70, n_estimators=100, random_state=123) rfgs_clf.fit(X_train_res, y_train_res) mean_rf_cv_score = np.mean(cross_val_score(rfgs_clf, X_train_rus, y_train_rus, cv=3)) print(f"Mean Cross Validation Score for Random Forest Classifier: {mean_rf_cv_score :.2%}") which yielded a similar cross-validation score:
Mean Cross Validation Score for Random Forest Classifier: 79.76%
If you read my prior post, I'd built an evaluation tool that let me quickly visualize outcomes:

Again, if you read my prior post, you would know how to read this incredibly colorful result shows that it is definitely not overtrained, and training accuracy is only 77%... whats most distressing is that the thing we are trying to identify is a true positive which is located in the bottom right hand corner. That value reads .26 - not good. Something is wrong here, and it
honestly lead to a lot of trial and error. In hindsight, I see that the class_weight was set to 'balanced'. This would help address the imblance and is what I ended up doing in my final model. I found it and lesson learned: read the entire best estimators report.
I tried using a technique called SMOTE for under and oversampling the data to try to combat the hyper imbalance. This is where you 'synthesise' data based on what you have. It took forever in gridsearch , using this data for some reason so I abandoned the gridsearch and began to test out different theories based on my prior gridsearchd suggestion. I didn't make my tree that deep at first to see what happened, and used .3 as a value for max_features but kept my n_estimators at 100 and implemented the class_weight as balanced this time:
time = fn.Timer()
time.start()
rf_clf2 = RandomForestClassifier(criterion='gini', max_depth=5, max_features=.3, n_estimators=100, class_weight='balanced', random_state=111)
rf_clf2.fit(X_train_res, y_train_res)
time.stop()yh2 = rf_clf2.predict(X_test)
fn.evaluate_model(X_test, y_test, yh2, X_train_res, y_train_res, rf_clf2)
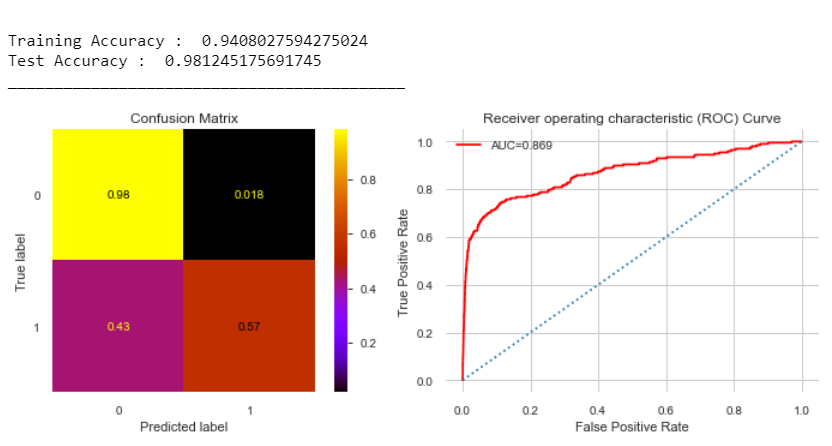
Heyyy better than a coin-flip for predicting the TPR (True Positive Rate) which went up, as did the training accuracy. Looking at the AUC value, we can trust this model.
I played with this a little more and the best model I was able to achieve was this one:
time = fn.Timer()
time.start()
rf_clf8 = RandomForestClassifier(criterion='gini', max_depth=2, max_features=.45, class_weight='balanced',n_estimators=80, random_state=111)
rf_clf8.fit(X_train, y_train)
time.stop()Where I made the depth really shallow, increased the max_features to .45 and thinned out my trees to 80. In each case 'gini' was the best criterion. I ended up sacrificing a bit of accuracy but kept it slightly above 95%. From the absolute baseline, I was able to increase the TPR by .53 - so I guess having .64 TPR isn't horrible. It could be better. One way to improve this is to collect more data to address the imbalance. I can do that now since I imagine we have a lot more people that have tested positive for COVID19 unfortunately.

I needed to revisit how I went about tackling this problem(s), and now remember the pain of it all. The biggest problem was the imblanced, and scikit learn has a hyperparameter for that. I hope my pain helps you with how you'd think about tuning your tree or even get inspired on how to handle a problem where you have a hyper-imbalance.
Drop a line... let me know what you'd like to see.
More (detailed) reading:
Bruce Brownlee is amazing in explaining things like RandomForest / Ensemble.
I found this link helpful too when it came to comparing gini with entropy.



Comments