For the SQL curious:
- Andrea Osika
- Nov 5, 2020
- 6 min read

Updated: Jan 25, 2021
I've been studying data science for about a year now. I'm ready to conquer data science tasks big and small and look at ways I can use my skills in regression, classification, and natural language processing to help organizations solve problems. Data can tell stories, illustrate gaps, and help predict future outcomes.
Before you can use the data to do all the things it can do, you need to GET the data. There are all kinds of ways to obtain data - web scraping, making observations, or querying databases to name a few. I'm finding that querying databases is what the world does for the most part... and a lot of it done using SQL. Basically, if you're gonna get data, you need to know SQL.
Maybe you've seen those three letters SQL and wondered how you say it out loud. Is it spelled out S-Q-L or do you just say "see-quel"? Well, in the name of peace... both. Back in the 1970s, IBM created a Structured English QUEry Language and called it SQUEL... get it? Time passes and it gets changed to SQL since "SEQUEL" was already trademarked by Hawker Siddeley, a UK aircraft company. Personally, I hear "see-quel" a lot more in my day, now that I spend more time in the land of data. Today Structured Query Language (SQL) is the most popular computer langue used to create, modify, and retrieve data in relational databases which I'll get to in a minute.
The premise of SQL like its original name eluded to, is to be a lot more like natural language than other programming languages. While it's not exactly conversational, even someone who has no programming experience could follow the logic behind this example query:
Query: Find the names of employees in Dept. 50. (the column name is DNO);
SELECT NAME
FROM EMP
WHERE DNO = 50;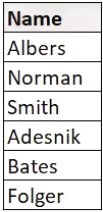
The command would go to the database and query all records with the department number of 5o from the 'EMP' table and return the names. See how it works from the bottom to the top? This way the query doesn't have to go through every single row to find what it needs. It saves computational time and energy this way. And, you might notice:
They aren't in order... if you wanted that, you'd have to add another command after everything else.
ORDER BY - which returns a list in ascending order. If you want them in descending order you'd add a DESC after the column you called after the ORDER BY clause (on the last line right before the semi-colon in the example below). If you'd explicitly wanted to call out ascending for any reason you'd use ASC.
For now, it makes sense to just let it be implied:
SELECT NAME
FROM EMP
WHERE DNO = 50
ORDER BY NAME;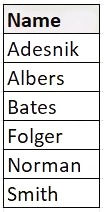
That's better. I like things in order. However, you can do that in excel at the click of a button... without learning a programming language. What makes SQL so special is its ability to slice through large amounts of data, and in most cases, not from the same table. Usually, there are a whole collection of tables. But before we get to the multiple table thing:
How do you create a table in the first place?.
CREATE TABLE:
You can see in the code block below that when you're creating a table after you call CREATE TABLE and enter the table name, you open up some parentheses and add each column name, followed by the data type.
CREATE TABLE groceries (id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, name TEXT, quantity INTEGER );You see after the first column called in the example above that id is an integer. Only for this first column do you see 'PRIMARY KEY' after the data type. It's a good idea to have a unique identifier called a primary key in each table to keep track of unique values. Actually - you need one. It's how these tables relate to each other. When you add that term PRIMARY KEY after the name and data type..and you don't want to keep track of this, you can use AUTOINCREMENT. Now when you add a new entry, you won't have to track or enter a value each time. ('whew') A comma follows each column addition, and the list of columns is closed up with that right parentheses. That semicolon that I've not explicitly called out until now which is the signal to SQL that "This is the end of the query."
If you've never written or read SQL, you might be getting the hang of it. Let's talk more about how these tables relate to each other.
I mentioned briefly that SQL is a relational database - it's what makes it so powerful! Relational databases (also derived from IBM in the 1970s) by definition have two main qualities. They:
Present the data to the user as relations (a presentation in tabular form, i.e. as a collection of tables with each table consisting of a set of rows and columns);
Provide relational operators to manipulate the data in tabular form.
All the data relates to each other, but it doesn't make sense to keep everything in one place because - computationally - that's expensive. Instead, data is stored in separate tables based on relevance. Each table can be used alone or conjointly - SQL uses only what it needs - it's an efficiency freak!
A schema is supporting documentation for a series of tables. It can include tables, views, stored procedures, functions, indexes, and triggers. Here's a view of one I used in a past project. See how all the primary keys and relations are noted? This one is pretty complex, but it gives you a sense of how the different tables can relate to each other.
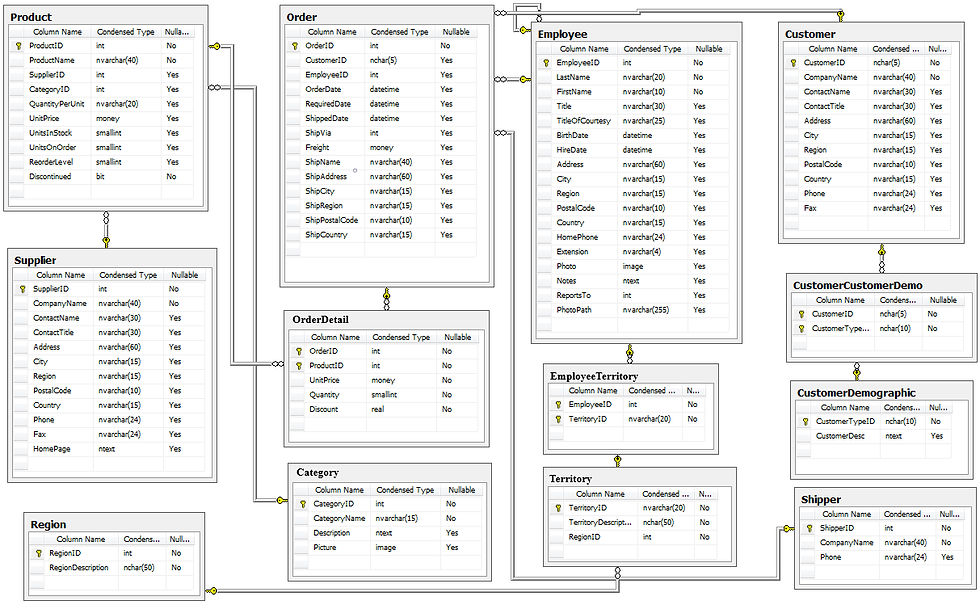
The primary key I introduced you to in one table can be a foreign key in another. While a primary key may exist on its own, a foreign key must always refer to a primary key. See in the view of the 'Product' table (upper left-hand corner from the image above), how ProductID is called out as the primary key with the icon, and in the 'Supplier' table (just below 'Product') the primary key is SupplierID? That SupplierID is a foreign key in the 'Product' table, since it's not the unique identifier and also how these two tables relate to each other or can JOIN. It can get overwhelming if this is new - believe me, I know!
Consider these two tiny tables for the sake of simplicity:
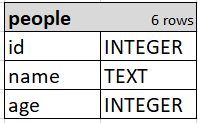

To create a query to find all the 'hobbies' of the 'people' table, you can JOIN the two. The secondary table in a query is also called the right table. In the query below, 'hobbies' is the right table since it comes after JOIN. In this case, people_id is a foreign key in 'hobbies' and relates to the 'people' primary key of id. Each column is identified by calling it after the table and adding a '.':
SELECT people.name, hobbies.name
FROM people
JOIN hobbies
ON people.id=hobbies.people_id;Here we are asking for the names of all the people and hobbies from the 'people' table by joining 'hobbies' on the primary and foreign keys of each where they are the same... Do you get it? Yes?? If you follow this, you are learning SQL right now! Woot! The resulting table would be 11 rows and show all the records from the 'hobbies' table.
If you wanted to find all the hobbies of one person you'd add that WHERE clause we'd used in our very first query:
SELECT people.name, hobbies.name
FROM people
JOIN hobbies
ON people.id=hobbies.person_id
WHERE people.name = "Janet Jackson";This would only return Janet's hobbies. I wonder what they are besides singing and dancing?
There are many kinds of JOINS:

Real quick an explanation of each is below, and if you want more go here:
An inner join only returns the data that overlaps both tables,
A full join returns all the data from both tables. If there is no data relating to a specific column, a null value is returned in that row.
Left joins return all the data from the first table queried or the 'left' table
Right joins return the data in the second table queried or 'right' along with any overlapping data in the left table. These are very rarely used.
There are other things you can do with SQL like adding using the SUM clause or finding the average AVG and you can use other mathematical calculations as well like COUNT to find how many records fall into the query. These are called aggregate functions.
SIMPLE MATH FUNCTIONS IN SQL:
Let's say you like exercising a lot (I DO!) and you're looking for target heart ranges. Your max heart rate can be calculated by subtracting your age from 220. Let's say we're looking to find your target heart rate, or 50% - 90% of your max heart rate and you're 40 years old:
/* 50-90% of max*/
SELECT COUNT(*)
FROM exercise_logs
WHERE heart_rate >= ROUND(0.50 * (220-40))
AND heart_rate <= ROUND(0.90 * (220-40));Again, see how it just kind of reads like language? Here we're just asking for the count - (anything with an * means "give me everything" and is way easier to type) from 'exercise_logs' where the heart rate is more than 50% of max rate and less than 90%. The AND clause returns records that meet BOTH criteria. If you used OR, it would return records that met either.
These are just the tip of the iceberg! Once you get these, you can begin to group data and begin more complex queries. That, I'll save for my next blog. Get excited!
Additional reading and sources:
Sources not credited via links in blog: Edureka, JOINS Blog Sept 2020 ,
CS exhibitions ..and this is a great SQL resource
If you're super excited and inspired, Khan Academy offers an open-source course to get you started!



Comments